Very nice description and good results -- although it took a while for me to understand just what impostors were (being unfamiliar with the jargon, but familiar with image-based rendering concepts in my research).
I'm curious, implementation-wise, what would need to be done to do this in a more unstructured way. Rather than having a regular polyhedron and a corresponding texture per polyhedron vertex, it would be interesting to use automatic measures of viewpoint entropy to select a smaller number of views that still adequately describe the object to some level of quality. [0] Rather than it being an octahedron, it would be some other irregular shape of points projected onto a unit sphere, from which a 3D convex hull is computed.
The one issue I can think of is that you'd need a way to quickly determine which triangle of that hull the camera is inside (to get the three surrounding views). Is there a way to do that all in shaders without costly raycasts on the CPU side?
Correct me if I'm wrong, but I thought the original idea of impostors was to use dynamic billboards for distant objects, and regenerate them on the fly as the angle or distance changed enough to make the error visible? Although this certainly still qualifies in the basic sense of "render a simple thing that looks like the complex thing." I guess it also lets you discard the geometry of the object (assuming you don't let the camera get close enough that you have to switch to a fully rendered view) which I can see saving a ton of memory for very detailed objects.
I remember reading a bunch of stuff a decade or so ago about image-based rendering using techniques like this for super-high-detail large scale scenes, is that all run-of-the-mill graphics engine stuff now or did we get enough horsepower to just keep throwing polygons at it?
It should be possible to also bake a UV map alongside the impostors, based on the relative angles between the ray cast from every impostor pixel and the surface normals of the triangles of the model being baked. That UV map should double the memory requirements. However it means that you can do dynamic lighting, by sampling the lights at the impostor's origin in the world, and building up a list of tuples of vectors containing things like color, angle, spread, direction, intensity, and applying those to the UV map - and ultimately to the impostor sprite, similarly to bump maps. This would allow the impostors to be well-lit, although I'm not certain how you would account for shadows or highly directional light sources.
I also wonder, to what extent can this method of impostor rendering actually replace ordinary rendering? There is clearly a tradeoff between triangle count and sprite memory. It is possible to stream in higher res textures to replace low-res stand-ins. How feasible would it be to ship GPUs with ridiculous amounts of memory, that are optimized primarily for impostor rendering?
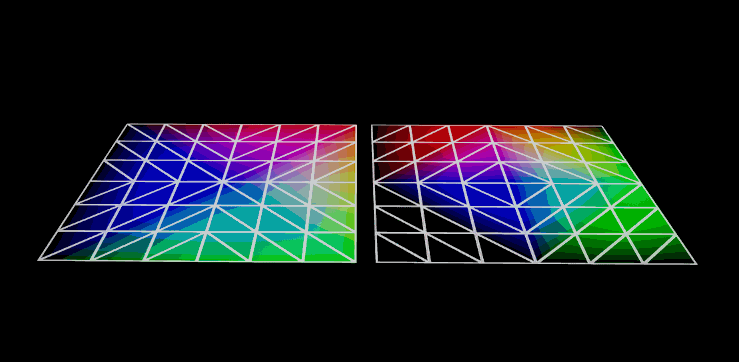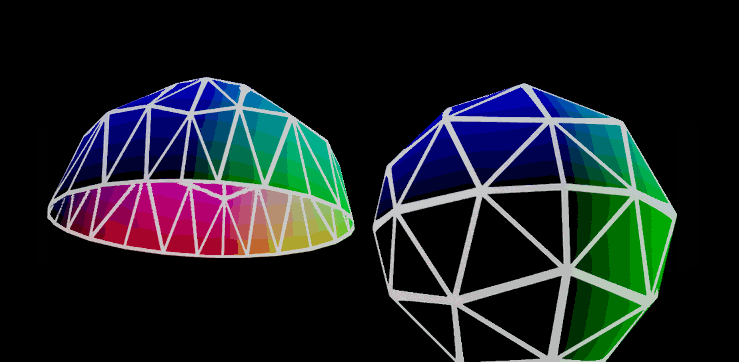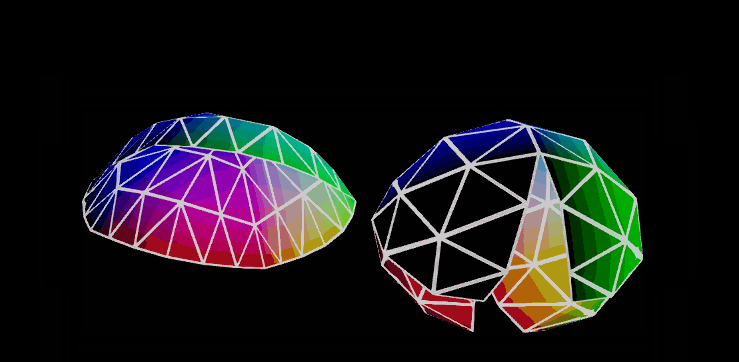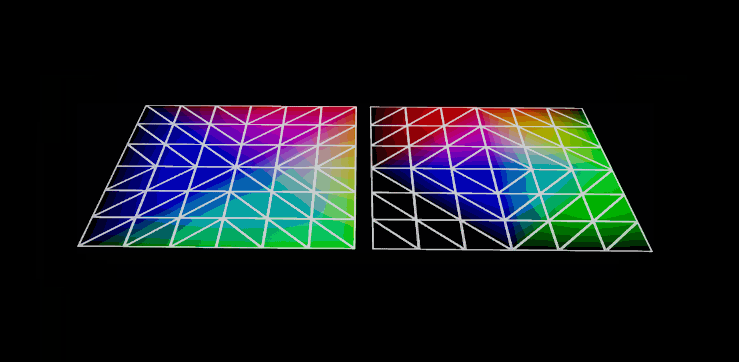
I am assuming that this is because that sphere-like object is generated by subdividing and inflating an octahedron, rather than the "sphere" primitive found in a lot of 3d programs. Duckgoing for "octahedral sphere" brings up things like a tutorial on "creating better spheres by subdividing an octahedron".
Those meshes are made by subdividing an octahedron. Approximating an sphere like that has the nice property that the triangles in each subdivision level have the same surface area, and you can use the same underlying texture for all the levels since in the 2D projection the sub triangles are also regular subdivisions of their parents.
Those billboards are an alternative (the more traditional) impostor type. The octahedral impostors replace these billboards with a geodesic polyhedron of octahedral symmetry. Basically it subdivides the sides of an octahedron to approximate a sphere.
Not really. The octahedron defines the positions you pre-render the impostors from. The actual rendering uses a flat plane (like a regular billboard) but with a parallax shader and depth offset to make it look bent.
Second Life still can't even generate ordinary billboards automatically. Most low level of detail models in Second Life are generated with the Decimate tool in Blender, which does a terrible job. People decimate all the way down to one triangle, which looks terrible. Better level of detail models have to be handmade. It's so 1990s.
{kind=link}
I'm curious, implementation-wise, what would need to be done to do this in a more unstructured way. Rather than having a regular polyhedron and a corresponding texture per polyhedron vertex, it would be interesting to use automatic measures of viewpoint entropy to select a smaller number of views that still adequately describe the object to some level of quality. [0] Rather than it being an octahedron, it would be some other irregular shape of points projected onto a unit sphere, from which a 3D convex hull is computed.
The one issue I can think of is that you'd need a way to quickly determine which triangle of that hull the camera is inside (to get the three surrounding views). Is there a way to do that all in shaders without costly raycasts on the CPU side?
[0] "Automatic View Selection Using Viewpoint Entropy and its Application to Image-Based Modelling", http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.96....