So - for those deeper into security - is this useful?
"Graviton3 processors also include a new pointer authentication feature that is designed to improve security. Before return addresses are pushed on to the stack, they are first signed with a secret key and additional context information, including the current value of the stack pointer. When the signed addresses are popped off the stack, they are validated before being used. An exception is raised if the address is not valid, thereby blocking attacks that work by overwriting the stack contents with the address of harmful code. We are working with operating system and compiler developers to add additional support for this feature, so please get in touch if this is of interest to you"
Very useful, depending on the implementation and potential trade-offs. If the performance is good, this is a nice extra layer that makes return-oriented programming more difficult. Combined with NX bits, it really raises the difficulty in developing/using many types of exploits.
(it's not impossible to bypass, I'm vaguely aware it's been done on Apple's new chips that implement a similar (the same?) ARM extension, but there's no perfect security)
Performance is what I wonder about. The idea sounds good, but what crypto scheme can perform encryption of a signature both securely and fast enough to keep up with every pointer pushed on the stack?
> On average, encoding addresses and verifying them at each
indirect branch using the dedicated blraaz and braaz
instructions yields a performance overhead of 1.50%. The
protection of the link between indirect control-flow transfers
induces a runtime overhead of 0.83% on average. For the
combination of both protection mechanism, we measured an
average performance overhead of 2.34%.
Pointer authentication has been around for several years already. As with many things in hardware, though, it takes time for the software ecosystem around it to mature. Still, I've found it to be quite influential.
Here are a couple "real world" examples--
Project Zero had a blogpost about some of the weaknesses on the original Pointer Auth spec [0], and even had a follow up [1].
Here is an example of what some mitigation might look like, showing how gets(), which is a classically trivially vulnerable primitive, becomes not-so-trivial (but still feasible enough to do in a blogpost, obviously) [2].
Cost-wise, in terms of both hardware and software, it's rather cheap. The hardware to support this isn't too expensive, about on par with a multiplier. On the software end, like I said, it's taken some time to mature and gotten to a pretty good state IMO, with basically all compilers providing simple usage since 2019-- just turn on a flag!
ARM also did a performance vs. ROP gadget reduction analysis [3]. The takeaway is, as others have mentioned, while it doesn't completely mitigate, it does heavily increase the complexity for rather cheap.
In fact, I'm rather annoyed Amazon didn't include this feature on Graviton2, and to claim it as new or innovative on their end feels just like marketing speak. Any CPU that claims to be ARMv8.5-a compliant *must* have this feature, and that's been around for quite a few years now.
This isn't something I know a lot about but it sounds like the idea of a shadow stack [0] but implemented with crypto. See also Intel CET (for Control-flow Enforcement Technology). [1]
It would take the heat off for mitigating buffer overflow CVEs in a rushed way. There are many of those that give remote code execution, so typically a frenzied patching exercise. A little more time to do the patching in a more deliberate way would be nice.
I think in some cases this would effectively mitigate a vulnerability entirely. If you require control over the return address you're basically shit out of luck. A buffer overflow at that point is going to have to target some other function pointer or data, which may not be feasible in a given function.
>Graviton3 will deliver up to 25% more compute performance and up to twice as much floating point & cryptographic performance. On the machine learning side, Graviton3 includes support for bfloat16 data and will be able to deliver up to 3x better performance.
>First in the cloud industry to be equipped with DDR5 memory.
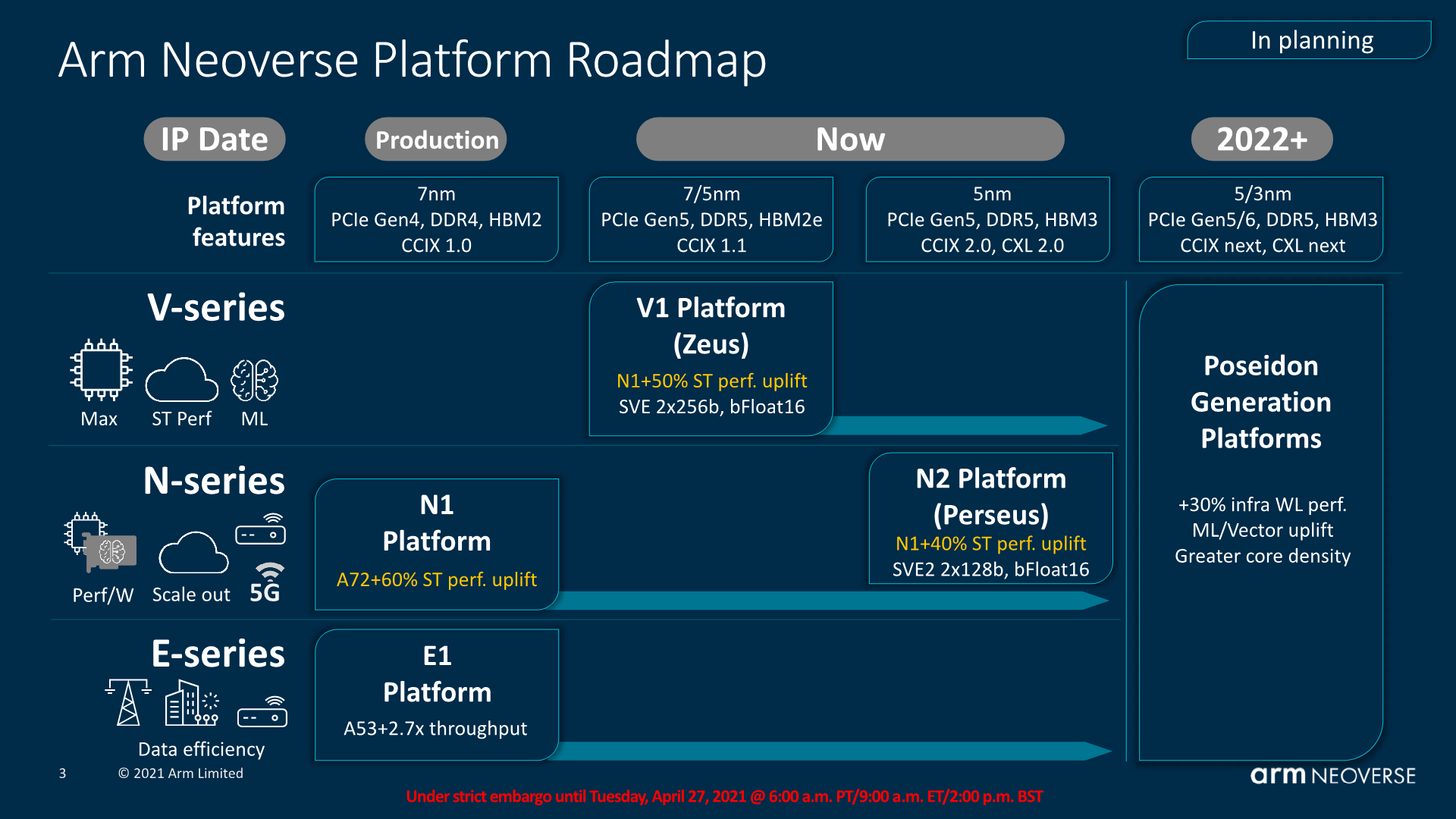
Quite hard to tell whether this is Neoverse V1 or N2. Since the description fits both . But this SVE extensions will move a lot of workload that previously wont suitable for Graviton 2
Edit: Judging from Double floating point performance it should be N2 with SVE2. Which also means Graviton 3 will be ARMv9 and on 5nm. No wonder why TSMC doubled their 5nm expansion spending. It will be interesting to see how they price G3 and G2. And much lowered priced G2 instances will be very attractive.
I’m going to look up what SVE extensions are, but before I do, how much work (as a proportion of all work done on EC2) couldn’t be done on G2? I generally go off the assumption that most EC2 instances are hosting web servers and database servers, along with a handful, relatively, of CI servers and perhaps a sprinkling of video transcoders, 3D renderers and ML trainers. How much of that work can’t be done with the operations supported by G2? Is it just the long tail?
SIMD instructions, basically in the Intel x86 world that is like SSE4.
> Can’t be done on G2
Probably close to zero? Assuming your code compiles and run on ARM. It is just a matter of whether that operation is fast or slow, or in AWS terms whether it is cost effective since those EC2 instances are priced differently. And that cost includes porting and testing your software on ARM. For a lot of Web Server workload, G2 nearly offer 50% reduction in cost at the same or better performance. At the scale of twitter it absolutely makes sense to move those operation over. There are some workloads that dont like well things like 3D Renderers, or software that has too many x86 specific optimisation and takes too. much man power to port. So yes in that sense it will be a long tail of x86 instances. ( Assuming that is what you are referring to long tail )
Where are Google and Azure with ARM instances? It's been nothing but crickets for years now... this is starting to get silly that their customers can't at least start getting workloads on a different architecture, nevermind get better performance per dollar, etc. too. The silence is deafening.
Remember Amazon brought Annapurna Labs in 2015. And only released their first Graviton instances in 2018. The lead time for a Server CPU product is at least a year even when you have blueprints. That is ignoring fab capacity booking and many other things like testing. And without scale ( AWS is bigger than GCP and Azure combined ) it is hard to gain competitive advantage ( which often delays management decision making ).
I think you should see Azure and GCP ARM offering in late 2022. Marvel's exit statement on ARM server SoC pretty much all but confirmed Google and Microsoft are working on their own ARM offering.
In terms of physical servers. I believe Chinese cloud providers, and their monster CNDs (China has terribly slow Internet, and superlocal CDNs are the only way out there) overtook AWS quite a few years ago.
There is also the common practice of not including discounts in revenue. There is a reason companies talk about revenue instead of net sales or net income.
I've never seen AWS give discounts comparable to what Azure provided. Especially to larger companies they want the brand recognition from.
Microsoft’s “cloud business” is not at all comparable to AWS or GCP. It includes all manner of other product that can’t be reasonably classified as cloud compute. AWS remains significantly larger than either azure or GCP when measured by either revenue or raw compute.
"The second phase will see these entities develop custom integrated chips and System on a Chip (SoC) with "lower power consumption, improved performance, reduced physical size, and improved reliability for application in DoD systems."
Doesn’t IBM also offer a bunch of weird architectures that can’t be found anywhere else? One day I was looking up some old PowerPC and s390 architectures that are supported by a lot of docker images, trying to figure out why anyone would want them, and it appears the answer is that they’re used in IBM mainframes.
I was wondering how they were going to manage the fact that AMDs Zen3 based instances would likely be faster than Graviton2. Color me impressed. AWS' pace of innovation is blistering.
I don't know. I prefer it when companies actually give the technical details.
> While we are still optimizing these instances, it is clear that the Graviton3 is going to deliver amazing performance. In comparison to the Graviton2, the Graviton3 will deliver up to 25% more compute performance and up to twice as much floating point & cryptographic performance. On the machine learning side, Graviton3 includes support for bfloat16 data and will be able to deliver up to 3x better performance.
This means nothing to me. Why is there more floating point and cryptographic performance? Did Amazon change the Neoverse core? Is this N1 cores still? Did they tweak the L1 caches?
I don't think Amazon has the ability to change the core design unfortunately. This suggests to me that maybe Amazon is using N2 cores now?
But it'd be better if Amazon actually said what the core design changes are. Even just saying "updated to Neoverse N2" would go a long way to our collective understanding.
AWS re:Invent is this week. This was announced as part of the CEO's keynote. I am sure we will get more details throughout the week in some of the more technical sessions.
N2 does not use 256b SVE2, though its cousin Neoverse V1 does. I think there's a very real chance that Grav3 is actually V1, not N2. (N2 uses 128b SVE vectors, as does the Cortex-A710 it's based on.)
Aren't the Zen3 instances still faster than Graviton 3? DDR5 is interesting, and while lower power is nice, the customers don't benefit from that much, mostly AWS itself with its power bill. I haven't seen pricing yet, but assume AWS will price their own stuff lower to win customers and create further lock-in opportunities (and even take a loss like with Alexa).
I would guess price/performance matters more than peak performance for a lot of use cases. With prior Graviton releases, AWS has made it so they are better price/performance. Keep in mind that a vCPU on Graviton is a full core rather than SMT/Hyperthread (half a core).
> Aren't the Zen3 instances still faster than Graviton 3?
Irrelevant.
The vast majority of applications running in the cloud are business applications that struggle to saturate the CPU and waste most of the CPU cycles idlying by in epoll/select loops. Unless you need HPC, you do not need the fastest CPU, either.
> create further lock-in opportunities
Don't like AWS/Graviton? Take your workload to the Oracle cloud and run it on Oracle ARM.
Don't like ARM? If your app is interpreted/JIT'd (e.g. Python/NodeJs) or byte code compiled (JVM), lift and shift it to the IBM cloud and run it on a POWER cloud instance – as long as IBM offers a price-performance ratio comparable to that of AWS/Graviton or you are willing to pay for it.
On that note being able to rent a 160 core machine for $1.6/hour on Oracles cloud service is really impressive. If you have an integer intensive workload (i tested SAT solving) the Ampere A1 machine Oracle rents out are really competitive.
I think the idea is by attracting new customers to EC2 via performance/price, and then enticing them to integrate with other harder-to-leave AWS services
What's the motivation behind this question? Or why do you think Amazon wants to create lockin for Graviton processors.
Note that graviton represent a classic "disruptive technology" that is outside of the main stream market's "value network". I.e., it provides something that is valuable to marginal customers who are far from the primary revenue source of the larger market.
Yes, that's the problem. Graviton and M1 are competitive with x86. What about the rest of the ecosystem? Not so much. All the promising server projects have been canceled so far. You'll have to wait for Microsoft or Google to develop their own competitive ARM server CPU or migrate back to x86.
> Where is this narrative that Zen 3 instances are faster than Graviton 3 instances coming from?
Various benchmarks have shown EPYC Milan performing well compared to contemporary Xeon and ARM-based processors, but the most direct comparison that I've seen was when Phoronix compared Graviton2 M6g instances to GCP's EPYC Milan-powered T2D instances.[1] The T2D instances beat the equivalent M6g instances across the board, oftentimes by substantial margins.
Of course, that's comparing against Graviton2, not Graviton3, but the performance delta is wide enough that T2D instances will still probably be faster in most cases.
Unfortunately those claims don't translate to servers, because the IO die's power usage increased and perf/w isn't much better [1]. Do the math and you get around 14% gain in SPEC MT workloads.
Nice wording with 'per core performance'. We had difficulties properly conveying this point in our product when comparing our CI runners[1] to GitHub Actions CI Runner. I will be using it in our next website update. Tack
Honestly, they’re not innovating so much as forcing a product market fit that everyone knew existed, but didn’t have the business case to develop without a hyperscalar anchor customer (like AWS!)
If anything, this is just another data point that shows how truly commoditized tech is. I just worry what happens when Amazon decides to “differentiate” after they lock you in.
I really hate it that big companies are rolling their own CPU now. Soon, you're not a serious developer if you don't have your own CPU. And everybody is stuck in some walled garden.
I mean, it's great that the threshold to produce ICs is now lower, but is this really the way forward? Shouldn't we have separate CPU companies, so that everybody can benefit from progress, not only the mega corporations?
>I really hate it that big companies are rolling their own CPU now. Soon, you're not a serious developer if you don't have your own CPU. And everybody is stuck in some walled garden.
It is still just ARM. You can buy ARM chip everywhere. There is no walled garden.
> Shouldn't we have separate CPU companies, so that everybody can benefit from progress,
You are benefiting the same CPU design from ARM, and same Fab improvement from TSMC. Amortised across the whole industry. Doesn't get any better than that.
> It is still just ARM. You can buy ARM chip everywhere.
Only large companies can build CPUs based on ARM. Also, now companies might rely on everything in vanilla ARM, but soon they will be adding parts of their own ISA, improvements to the memory hierarchy, a GPU, or perhaps even their own management engine to keep an eye on things or to keep things locked down.
> There is no walled garden.
There is huge potential for walled gardens, just look at Apple.
>Only large companies can build CPUs based on ARM....
Only large companies can build any modern CPUs.
> improvements to the memory hierarchy, a GPU, or perhaps even their own management engine
None of these has anything to do with ISA nor ARM. As a matter of fact adding any of these does not contribute to lock in. They are ( potentially ) fragmentation in terms of optimisation requirement.
If I am inferring correctly, the only thing that wouldn't count as locked down and walled garden by your definition would be a total open source design from Hardware to Software.
> If I am inferring correctly, the only thing that wouldn't count as locked down and walled garden by your definition would be a total open source design from Hardware to Software.
No. I'm totally fine with CPUs with fully open documentation and preferably designed by a company that specializes in CPUs. Open documentation + liberal license should allow other CPU manufacturers to compete based on the same ISA.
What I don't want is involvement of the vendor after I have bought my CPU (other than updates), or any kind of lock-in or dominance of one vendor for my ISA or dark patterns. Or drivers/updates that only work on a specific OS and thus are unusable if I decide to write my own OS for the CPU. Updates should be open (written in the language of the documentation) so the world can see if/where the company messed up.
While it's difficult to do in your own home, you don't have to be Amazon or Apple sized to make your own ARM-based CPUs. A few dozen employees can do it.
You can buy Ampere Arm CPUs that are based on the same core as AWS Graviton2. And in general mobile CPUs are a generation ahead of server architecturally.
Apple M1 isn't in a proprietary walled garden, it's a general purpose computer like any good old x86 laptop. It's not designed with industry standards in mind and doesn't have any official documentation on internals, but it's not locked down in any way, and reverse engineering is solving the documentation problem already.
(Also Qualcomm Snapdragon is a far more cursed platform internally.)
I mean, it's just ARM - pretty standard architecture these days. If the big companies want to compete on chip design, I don't see it as all that different from AMD, Intel (and Via if you count them) competing on x86-compatibles.
AMD/Intel/Via/IBM/ARM are in horizontal competition on chip design, Amazon/Google/Microsoft/Apple are in vertical competition on chip design. Vertical competition typically results in far less ability for the market to optimize.
Compare for instance the Zen 3 upset vs the M1 upset. Zen 3 allowed the market to pick what they thought was the best CPU, the M1 allowed the market to pick if they wanted to buy an entire computer, OS, and software set because the CPU was good. Similarly with Graviton and Amazon, you can't just say Amazon is competing the same as Via, their interest is in selling the AWS ecosystem not in providing the best individual components. Same with Google and their custom chips and Microsoft with theirs now. Yes many are "just ARM" but due to custom extensions/chips and (in some cases) lack of standard ARM features that doesn't mean they are the same ARM.
Of course that's not to argue it's wrong because it's vertical integration, many will think that's the better way to make complicated products, but that's not the point - the way big companies are competing on chip design is very different than if one acted like an AMD/Intel/Via competitor to actually compete in the chip space instead of a larger space.
> Yes many are "just ARM" but due to custom extensions/chips and (in some cases) lack of standard ARM features that doesn't mean they are the same ARM.
This is a stretch at best.
Linux running on M1, Graviton2 (and, soon, Graviton3), Raspberry Pi 3/4 runs same, aarch64 compiled, user space binaries. NetBSD running on M1 and on Raspeberry Pi 3/4 runs same, aarch64 compiled, user space binaries. ARM, the company, enforces the µ-architecture compatibility through the licensing. Just like Intel and AMD do.
The difference is perceptable at the hardware/kernel level; however the same is also true for nearly every new generation of Intel and AMD CPU's – at least some modifications are required in the kernel.
You are conflating software compatibility with hardware availability.
Most ARM vendors sell the equvialent of an electric bicycle when what you need is a van and there are only two viable manufacturers of vans but the first one doesn't sell to companies and the second one requires you rent the van.
I do point out that vendor-specific architectures were the norm for long time in the history and the sky didn't fall down. The x86 dominance was relatively short anomaly more than anything.
Thanks for the document, so the ARM marketing just confused me. ;-)
Yes N2 is more likely than V1. N2 has the better PPA ratio.
Own CPU core is very unlikely as I am not aware of any rumors which we would have notice before.
No benchmarks yet, but I can get 30% faster latency, on 2/3 the number of instances compared to c6g for the same uncompress/compress/write to Kafka workload.
So that's the c6g and c7g but x86 instances are still on c5. Will AWS ever release an x86 computing instance again or is this just a sign that x86 has reached peak performance on AWS?
"Up to 35 percent higher price performance per vCPU versus comparable M5a instances, up to 50 Gbps of networking speed, and up to 40 Gbps bandwidth of Amazon EBS, more than twice that of M5a instances."
"Larger instance size with 48xlarge with up to 192 vCPUs and 768 GiB of memory, enabling you to consolidate more workloads on a single instance. M6a also offers Elastic Fabric Adapter (EFA) support for workloads that benefit from lower network latency and highly scalable inter-node communication, such as HPC and video processing."
"Always-on memory encryption and support for new AVX2 instructions for accelerating encryption and decryption algorithms"
{kind=link}
"Graviton3 processors also include a new pointer authentication feature that is designed to improve security. Before return addresses are pushed on to the stack, they are first signed with a secret key and additional context information, including the current value of the stack pointer. When the signed addresses are popped off the stack, they are validated before being used. An exception is raised if the address is not valid, thereby blocking attacks that work by overwriting the stack contents with the address of harmful code. We are working with operating system and compiler developers to add additional support for this feature, so please get in touch if this is of interest to you"